FAQs
Answers to questions about general features, troubleshooting, usage, and more.
- General features
- What sets RAGFlow apart from other RAG products?
- Which embedding models can be deployed locally?
- Where to find the version of RAGFlow? How to interpret it?
- Why not use other open-source vector databases as the document engine?
- Differences between cloud.ragflow.io and a locally deployed open-source RAGFlow service?
- Why does it take longer for RAGFlow to parse a document than LangChain?
- Why does RAGFlow require more resources than other projects?
- Which architectures or devices does RAGFlow support?
- Do you offer an API for integration with third-party applications?
- Do you support stream output?
- Do you support sharing dialogue through URL?
- Do you support multiple rounds of dialogues, referencing previous dialogues as context for the current query?
- Key differences between AI search and chat?
- Troubleshooting
- Get a
Request error 404: undefinedwhen upgrading to v0.26.4 - How to build the RAGFlow image from scratch?
- Cannot access https://huggingface.co
Fail to access model(Ollama/xxxxx)MaxRetryError: HTTPSConnectionPool(host='hf-mirror.com', port=443)RuntimeError: Unable to start Tika server.Cannot stat '/etc/nginx/conf.d/ragflow.conf.python': No such file or directoryWARNING: can't find /ragflow/rag/res/borker.tmnetwork anomaly There is an abnormality in your network and you cannot connect to the server.Realtime synonym is disabled, since no redis connectionxxx tasks are ahead in the queue- For RAGFlow versions earlier than v0.26.0
- For RAGFlow v0.26.0 and later
- Why does my document parsing stall at under one percent?
- Why does my pdf parsing stall near completion, while the log does not show any error?
Index failure- How to check the log of RAGFlow?
- How to check the status of each component in RAGFlow?
Exception: Can't connect to ES cluster- Can't start ES container and get
Elasticsearch did not exit normally {"data":null,"code":100,"message":"<NotFound '404: Not Found'>"}Ollama - Mistral instance running at 127.0.0.1:11434 but cannot add Ollama as model in RagFlow- Do you offer examples of using DeepDoc to parse PDF or other files?
FileNotFoundError: [Errno 2] No such file or directory
- Get a
- Usage
- How to run RAGFlow with a locally deployed LLM?
- How to add an LLM that is not supported?
- How to integrate RAGFlow with Ollama?
- How to change the file size limit?
Error: Range of input length should be [1, 30000]- How to get an API key for integration with third-party applications?
- How to upgrade RAGFlow?
- How to switch the document engine to Infinity?
- Where are my uploaded files stored in RAGFlow's image?
- How to tune batch size for document parsing and embedding?
- How to accelerate the question-answering speed of my chat assistant?
- How to accelerate the question-answering speed of my Agent?
- How to use MinerU to parse PDF documents?
- How to configure MinerU-specific settings?
- How to use MinerU with a vLLM server for document parsing?
- How to use an external Docling Serve server for document parsing?
- How to use PaddleOCR for document parsing?
- How do I use Ollama with RAGFlow for local LLM inference?
General features
What sets RAGFlow apart from other RAG products?
The "garbage in garbage out" status quo remains unchanged despite the fact that LLMs have advanced Natural Language Processing (NLP) significantly. In its response, RAGFlow introduces two unique features compared to other Retrieval-Augmented Generation (RAG) products.
- Fine-grained document parsing: Document parsing involves images and tables, with the flexibility for you to intervene as needed.
- Traceable answers with reduced hallucinations: You can trust RAGFlow's responses as you can view the citations and references supporting them.
Which embedding models can be deployed locally?
Starting from v0.22.0, we ship only the slim edition and no longer append the -slim suffix to the image tag.
Where to find the version of RAGFlow? How to interpret it?
You can find the RAGFlow version number on the System page of the UI:
If you build RAGFlow from source, the version number is also in the system log:
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
2025-02-18 10:10:43,835 INFO 1445658 RAGFlow version: v0.15.0-50-g6daae7f2
Where:
v0.15.0: The officially published release.50: The number of git commits since the official release.g6daae7f2:gis the prefix, and6daae7f2is the first seven characters of the current commit ID.
Why not use other open-source vector databases as the document engine?
Currently, only Elasticsearch and Infinity meet the hybrid search requirements of RAGFlow. Most open-source vector databases have limited support for full-text search, and sparse embedding is not an alternative to full-text search. Additionally, these vector databases lack critical features essential to RAGFlow, such as phrase search and advanced ranking capabilities.
These limitations led us to develop Infinity, the AI-native database, from the ground up.
Differences between cloud.ragflow.io and a locally deployed open-source RAGFlow service?
cloud.ragflow.io demonstrates the capabilities of RAGFlow Enterprise. Its DeepDoc models are pre-trained using proprietary data and it offers much more sophisticated team permission controls. Essentially, cloud.ragflow.io serves as a preview of RAGFlow's forthcoming SaaS (Software as a Service) offering.
You can deploy an open-source RAGFlow service and call it from a Python client or through RESTful APIs. However, this is not supported on cloud.ragflow.io.
Why does it take longer for RAGFlow to parse a document than LangChain?
We put painstaking effort into document pre-processing tasks like layout analysis, table structure recognition, and OCR (Optical Character Recognition) using our vision models. This contributes to the additional time required.
Why does RAGFlow require more resources than other projects?
RAGFlow has a number of built-in models for document structure parsing, which account for the additional computational resources.
Which architectures or devices does RAGFlow support?
We officially support x86 CPU and nvidia GPU. While we also test RAGFlow on ARM64 platforms, we do not maintain RAGFlow Docker images for ARM. If you are on an ARM platform, follow this guide to build a RAGFlow Docker image.
Do you offer an API for integration with third-party applications?
The corresponding APIs are now available. See the RAGFlow HTTP API Reference or the RAGFlow Python API Reference for more information.
Do you support stream output?
Yes, we do. Stream output is enabled by default in the chat assistant and agent. Note that you cannot disable stream output via RAGFlow's UI. To disable stream output in responses, use RAGFlow's Python or RESTful APIs:
Python:
RESTful:
Do you support sharing dialogue through URL?
No, this feature is not supported.
Do you support multiple rounds of dialogues, referencing previous dialogues as context for the current query?
Yes, we support enhancing user queries based on existing context of an ongoing conversation:
- On the Chat page, hover over the desired assistant and select Edit.
- In the Chat Configuration popup, click the Prompt engine tab.
- Switch on Multi-turn optimization to enable this feature.
Key differences between AI search and chat?
- AI search: This is a single-turn AI conversation using a predefined retrieval strategy (a hybrid search of weighted keyword similarity and weighted vector similarity) and the system's default chat model. It does not involve advanced RAG strategies like knowledge graph, auto-keyword, or auto-question. Retrieved chunks will be listed below the chat model's response.
- AI chat: This is a multi-turn AI conversation where you can define your retrieval strategy (a weighted reranking score can be used to replace the weighted vector similarity in a hybrid search) and choose your chat model. In an AI chat, you can configure advanced RAG strategies, such as knowledge graphs, auto-keyword, and auto-question, for your specific case. Retrieved chunks are not displayed along with the answer.
When debugging your chat assistant, you can use AI search as a reference to verify your model settings and retrieval strategy.
Troubleshooting
Get a Request error 404: undefined when upgrading to v0.26.4
To resolve this issue, do either of the following:
- Pull the latest source code from the main branch, then pull and start the v0.26.4 image.
- Update
RAGFLOW_IMAGEfrominfiniflow/ragflow:latesttoinfiniflow/ragflow:v0.26.4in the .env file, then restart the service.
How to build the RAGFlow image from scratch?
See Build a RAGFlow Docker image.
Cannot access https://huggingface.co
A locally deployed RAGFlow downloads OCR models from Huggingface website by default. If your machine is unable to access this site, the following error occurs and PDF parsing fails:
FileNotFoundError: [Errno 2] No such file or directory: '/root/.cache/huggingface/hub/models--InfiniFlow--deepdoc/snapshots/be0c1e50eef6047b412d1800aa89aba4d275f997/ocr.res'
To fix this issue, use https://hf-mirror.com instead:
-
Stop all containers and remove all related resources:
cd ragflow/docker/
docker compose down -
Uncomment the following line in ragflow/docker/.env:
# HF_ENDPOINT=https://hf-mirror.com -
Start up the server:
docker compose up -d
Fail to access model(Ollama/xxxxx)
Ollama may time out or fail during its first model load due to memory constraints or out-of-memory (OOM). It is best to test your local model in isolation first. If sharing hardware with other services, memory exhaustion is likely. To resolve this, switch to a smaller model or increase RAM.
MaxRetryError: HTTPSConnectionPool(host='hf-mirror.com', port=443)
This error suggests that you do not have Internet access or are unable to connect to hf-mirror.com. Try the following:
-
Manually download the resource files from huggingface.co/InfiniFlow/deepdoc to your local folder ~/deepdoc.
-
Add a volumes to docker-compose.yml, for example:
- ~/deepdoc:/ragflow/rag/res/deepdoc
RuntimeError: Unable to start Tika server.
This error is almost always caused by Java not being installed or not accessible in the environment. See here for detailed instructions.
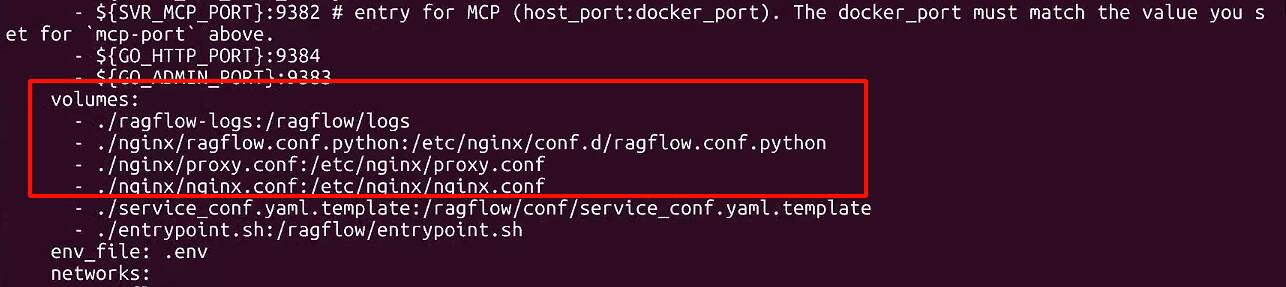
Cannot stat '/etc/nginx/conf.d/ragflow.conf.python': No such file or directory
To resolve this, either download the missing file from the corresponding tag on GitHub or update ~/ragflow/docker/docker-compose.yml as follows:
WARNING: can't find /ragflow/rag/res/borker.tm
Ignore this warning and continue. All system warnings can be ignored.
network anomaly There is an abnormality in your network and you cannot connect to the server.
You will not log in to RAGFlow unless the server is fully initialized. Run docker logs -f docker-ragflow-cpu-1.
The server is successfully initialized, if your system displays the following:
____ ___ ______ ______ __
/ __ \ / | / ____// ____// /____ _ __
/ /_/ // /| | / / __ / /_ / // __ \| | /| / /
/ _, _// ___ |/ /_/ // __/ / // /_/ /| |/ |/ /
/_/ |_|/_/ |_|\____//_/ /_/ \____/ |__/|__/
* Running on all addresses (0.0.0.0)
* Running on http://127.0.0.1:9380
* Running on http://x.x.x.x:9380
INFO:werkzeug:Press CTRL+C to quit
Realtime synonym is disabled, since no redis connection
Ignore this warning and continue. All system warnings can be ignored.
xxx tasks are ahead in the queue
For RAGFlow versions earlier than v0.26.0
- Clear the Redis task queue:
$ docker exec -it ragflow-redis /bin/bash
# In container
$ redis-cli -a infini_rag_flow
# In redis-cli
select 1
XGROUP DESTROY rag_flow_svr_queue rag_flow_svr_task_broker
XGROUP CREATE rag_flow_svr_queue rag_flow_svr_task_broker $ MKSTREAM
# When CREATE raises and error:
FLUSHDB
- If the parser remains stuck at 0%, restart the RAGFlow containers using one of the following methods:
# Option 1: Restart specific container
docekr restart docker-redis-1 docker-ragflow-cpu-1
# Option 2: Recreate containers via Docker Compose
docker compose -f docker/docker-compose.yml down
docker compose -f docker/docker-compose.yml up -d
# Option 3: Reset all Docker containers
# WARNING: Run this ONLY if your environment contains no other non-RAGFlow containers.
docker stop $(docker ps -aq)
docker rm $(docker ps -aq)
For RAGFlow v0.26.0 and later
- Clear the Redis task queue:
$ docker exec -it ragflow-redis /bin/bash
# In container
$ redis-cli -a infini_rag_flow
# In redis-cli
select 1
XGROUP DESTROY te.0.common_queue te.0.common_task_broker
XGROUP CREATE te.0.common_queue te.0.common_task_broker $ MKSTREAM
# When CREATE raises and error:
FLUSHDB
- If the parser remains stuck at 0%, restart the RAGFlow containers using one of the following methods:
# Option 1: Restart specific container
docekr restart docker-redis-1 docker-ragflow-cpu-1
# Option 2: Recreate containers via Docker Compose
docker compose -f docker/docker-compose.yml down
docker compose -f docker/docker-compose.yml up -d
# Option 3: Reset all Docker containers
# WARNING: Run this ONLY if your environment contains no other non-RAGFlow containers.
docker stop $(docker ps -aq)
docker rm $(docker ps -aq)
Why does my document parsing stall at under one percent?
Click the red cross beside the 'parsing status' bar, then restart the parsing process to see if the issue remains. If the issue persists and your RAGFlow is deployed locally, try the following:
-
Check the log of your RAGFlow server to see if it is running properly:
docker logs -f docker-ragflow-cpu-1 -
Check if the task_executor.py process exists.
-
Check if your RAGFlow server can access hf-mirror.com or huggingface.com.
Why does my pdf parsing stall near completion, while the log does not show any error?
Click the red cross beside the 'parsing status' bar, then restart the parsing process to see if the issue remains. If the issue persists and your RAGFlow is deployed locally, the parsing process is likely killed due to insufficient RAM. Try increasing your memory allocation by increasing the MEM_LIMIT value in docker/.env.
Ensure that you restart up your RAGFlow server for your changes to take effect!
docker compose stop
docker compose up -d
Index failure
An index failure usually indicates an unavailable Elasticsearch service.
How to check the log of RAGFlow?
tail -f ragflow/docker/ragflow-logs/*.log
How to check the status of each component in RAGFlow?
-
Check the status of the Elasticsearch Docker container:
$ docker psThe following is an example result:
5bc45806b680 infiniflow/ragflow:latest "./entrypoint.sh" 11 hours ago Up 11 hours 0.0.0.0:80->80/tcp, :::80->80/tcp, 0.0.0.0:443->443/tcp, :::443->443/tcp, 0.0.0.0:9380->9380/tcp, :::9380->9380/tcp docker-ragflow-cpu-1
91220e3285dd docker.elastic.co/elasticsearch/elasticsearch:8.11.3 "/bin/tini -- /usr/l…" 11 hours ago Up 11 hours (healthy) 9300/tcp, 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp ragflow-es-01
d8c86f06c56b mysql:5.7.18 "docker-entrypoint.s…" 7 days ago Up 16 seconds (healthy) 0.0.0.0:3306->3306/tcp, :::3306->3306/tcp ragflow-mysql
cd29bcb254bc pgsty/minio:RELEASE.2026-03-25T00-00-00Z "/usr/bin/docker-ent…" 2 weeks ago Up 11 hours 0.0.0.0:9001->9001/tcp, :::9001->9001/tcp, 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp ragflow-minio -
Follow this document to check the health status of the Elasticsearch service.
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
Exception: Can't connect to ES cluster
-
Check the status of the Elasticsearch Docker container:
$ docker psThe status of a healthy Elasticsearch component should look as follows:
91220e3285dd docker.elastic.co/elasticsearch/elasticsearch:8.11.3 "/bin/tini -- /usr/l…" 11 hours ago Up 11 hours (healthy) 9300/tcp, 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp ragflow-es-01 -
Follow this document to check the health status of the Elasticsearch service.
IMPORTANTThe status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
-
If your container keeps restarting, ensure
vm.max_map_count>= 262144 as per this README. Updating thevm.max_map_countvalue in /etc/sysctl.conf is required, if you wish to keep your change permanent. Note that this configuration works only for Linux.
Can't start ES container and get Elasticsearch did not exit normally
This is because you forgot to update the vm.max_map_count value in /etc/sysctl.conf and your change to this value was reset after a system reboot.
{"data":null,"code":100,"message":"<NotFound '404: Not Found'>"}
Your IP address or port number may be incorrect. If you are using the default configurations, enter http://<IP_OF_YOUR_MACHINE> (NOT 9380, AND NO PORT NUMBER REQUIRED!) in your browser. This should work.
Ollama - Mistral instance running at 127.0.0.1:11434 but cannot add Ollama as model in RagFlow
A correct Ollama IP address and port is crucial to adding models to Ollama:
- If you are on cloud.ragflow.io, ensure that the server hosting Ollama has a publicly accessible IP address. Note that 127.0.0.1 is not a publicly accessible IP address.
- If you deploy RAGFlow locally, ensure that Ollama and RAGFlow are in the same LAN and can communicate with each other.
See Deploy a local LLM for more information.
Do you offer examples of using DeepDoc to parse PDF or other files?
Yes, we do. See the Python files under the rag/app folder.
FileNotFoundError: [Errno 2] No such file or directory
-
Check the status of the MinIO Docker container:
$ docker psThe status of a healthy Elasticsearch component should look as follows:
cd29bcb254bc pgsty/minio:RELEASE.2026-03-25T00-00-00Z "/usr/bin/docker-ent…" 2 weeks ago Up 11 hours 0.0.0.0:9001->9001/tcp, :::9001->9001/tcp, 0.0.0.0:9000->9000/tcp, :::9000->9000/tcp ragflow-minio -
Follow this document to check the health status of the Elasticsearch service.
The status of a Docker container status does not necessarily reflect the status of the service. You may find that your services are unhealthy even when the corresponding Docker containers are up running. Possible reasons for this include network failures, incorrect port numbers, or DNS issues.
Usage
How to run RAGFlow with a locally deployed LLM?
You can use Ollama or Xinference to deploy local LLM. See here for more information.
How to add an LLM that is not supported?
If your model is not currently supported but has APIs compatible with those of OpenAI, click OpenAI-API-Compatible on the Model providers page to configure your model:
How to integrate RAGFlow with Ollama?
- If RAGFlow is locally deployed, ensure that your RAGFlow and Ollama are in the same LAN.
- If you are using our online demo, ensure that the IP address of your Ollama server is public and accessible.
See here for more information.
How to change the file size limit?
For a locally deployed RAGFlow: the total file size limit per upload is 1GB, with a batch upload limit of 32 files. There is no cap on the total number of files per account. To update this 1GB file size limit:
- In docker/.env, uncomment
# MAX_CONTENT_LENGTH=1073741824, adjust the value as needed, and note that1073741824represents 1GB in bytes. - If you update the value of
MAX_CONTENT_LENGTHin docker/.env, ensure that you updateclient_max_body_sizein nginx/nginx.conf accordingly.
It is not recommended to manually change the 32-file batch upload limit. However, if you use RAGFlow's HTTP API or Python SDK to upload files, the 32-file batch upload limit is automatically removed.
Error: Range of input length should be [1, 30000]
This error occurs because there are too many chunks matching your search criteria. Try reducing the TopN and increasing Similarity threshold to fix this issue:
- Click Chat in the middle top of the page.
- Right-click the desired conversation > Edit > Prompt engine
- Reduce the TopN and/or raise Similarity threshold.
- Click OK to confirm your changes.
How to get an API key for integration with third-party applications?
See Acquire a RAGFlow API key.
How to upgrade RAGFlow?
See Upgrade RAGFlow for more information.
How to switch the document engine to Infinity?
To switch your document engine from Elasticsearch to Infinity:
-
Stop all running containers:
$ docker compose -f docker/docker-compose.yml down -vWARNING-vwill delete all Docker container volumes, and the existing data will be cleared. -
In docker/.env, set
DOC_ENGINE=${DOC_ENGINE:-infinity} -
Restart your Docker image:
$ docker compose -f docker-compose.yml up -d
Where are my uploaded files stored in RAGFlow's image?
All uploaded files are stored in Minio, RAGFlow's object storage solution. For instance, if you upload your file directly to a dataset, it is located at <knowledgebase_id>/filename.
How to tune batch size for document parsing and embedding?
You can control the batch size for document parsing and embedding by setting the environment variables DOC_BULK_SIZE and EMBEDDING_BATCH_SIZE. Increasing these values may improve throughput for large-scale data processing, but will also increase memory usage. Adjust them according to your hardware resources.
How to accelerate the question-answering speed of my chat assistant?
See here.
How to accelerate the question-answering speed of my Agent?
See here.
How to use MinerU to parse PDF documents?
From v0.22.0 onwards, RAGFlow includes MinerU (≥ 2.6.3) as an optional PDF parser of multiple backends. Please note that RAGFlow acts only as a remote client for MinerU, calling the MinerU API to parse PDFs and reading the returned files. To use this feature:
- Prepare a reachable MinerU API service (FastAPI server).
- In the .env file or from the Model providers page in the UI, configure RAGFlow as a remote client to MinerU:
MINERU_APISERVER: The MinerU API endpoint (e.g.,http://mineru-host:8886).MINERU_BACKEND: The MinerU backend:"pipeline"(default)"vlm-http-client""vlm-transformers""vlm-vllm-engine""vlm-mlx-engine""vlm-vllm-async-engine""vlm-lmdeploy-engine".
MINERU_SERVER_URL: (optional) The downstream vLLM HTTP server (e.g.,http://vllm-host:30000). Applicable whenMINERU_BACKENDis set to"vlm-http-client".MINERU_OUTPUT_DIR: (optional) The local directory for holding the outputs of the MinerU API service (zip/JSON) before ingestion.MINERU_DELETE_OUTPUT: Whether to delete temporary output when a temporary directory is used:1: Delete.0: Retain.
- In the web UI, navigate to your dataset's Configuration page and find the Ingestion pipeline section:
- If you decide to use a chunking method from the Built-in dropdown, ensure it supports PDF parsing, then select MinerU from the PDF parser dropdown.
- If you use a custom ingestion pipeline instead, select MinerU in the PDF parser section of the Parser component.
All MinerU environment variables are optional. When set, these values are used to auto-provision a MinerU OCR model for the tenant on first use. To avoid auto-provisioning, skip the environment variable settings and only configure MinerU from the Model providers page in the UI.
Third-party visual models are marked Experimental, because we have not fully tested these models for the aforementioned data extraction tasks.
How to configure MinerU-specific settings?
The table below summarizes the most frequently used MinerU environment variables for remote MinerU:
| Environment variable | Description | Default | Example |
|---|---|---|---|
MINERU_APISERVER | URL of the MinerU API service | unset | MINERU_APISERVER=http://your-mineru-server:8886 |
MINERU_BACKEND | MinerU parsing backend | pipeline | MINERU_BACKEND=pipeline|vlm-transformers|vlm-vllm-engine|vlm-mlx-engine|vlm-vllm-async-engine|vlm-http-client |
MINERU_SERVER_URL | URL of remote vLLM server (for vlm-http-client) | unset | MINERU_SERVER_URL=http://your-vllm-server-ip:30000 |
MINERU_OUTPUT_DIR | Directory for MinerU output files | System-defined temporary directory | MINERU_OUTPUT_DIR=/home/ragflow/mineru/output |
MINERU_DELETE_OUTPUT | Whether to delete MinerU output directory when a temp dir is used | 1 (delete temp output) | MINERU_DELETE_OUTPUT=0 |
- Set
MINERU_APISERVERto point RAGFlow to your MinerU API server. - Set
MINERU_BACKENDto specify a parsing backend. - If using the
"vlm-http-client"backend, setMINERU_SERVER_URLto your vLLM server's URL. MinerU API expectsbackend=vlm-http-clientandserver_url=http://<server>:30000in the request body. - Set
MINERU_OUTPUT_DIRto specify where RAGFlow stores MinerU API output; otherwise, a system temp directory is used. - Set
MINERU_DELETE_OUTPUTto0to keep MinerU's temp output (useful for debugging).
For information about other environment variables natively supported by MinerU, see here.
How to use MinerU with a vLLM server for document parsing?
RAGFlow supports MinerU's vlm-http-client backend, enabling you to delegate document parsing tasks to a remote vLLM server while calling MinerU via HTTP. To configure:
- Ensure a MinerU API service is reachable (for example
http://mineru-host:8886). - Set up or point to a vLLM HTTP server (for example
http://vllm-host:30000). - Configure the following in your docker/.env file (or your shell if running from source):
MINERU_APISERVER=http://mineru-host:8886MINERU_BACKEND="vlm-http-client"MINERU_SERVER_URL="http://vllm-host:30000"MinerU API calls expectbackend=vlm-http-clientandserver_url=http://<server>:30000in the request body.
- Configure
MINERU_OUTPUT_DIR/MINERU_DELETE_OUTPUTas desired to manage the returned zip/JSON before ingestion.
When using the vlm-http-client backend, the RAGFlow server requires no GPU, only network connectivity. This enables cost-effective distributed deployment with multiple RAGFlow instances sharing one remote vLLM server.
How to use an external Docling Serve server for document parsing?
RAGFlow supports Docling in two modes:
- Local Docling (existing mode): install Docling in the RAGFlow runtime (
USE_DOCLING=true) and parse in-process. - External Docling Serve (remote mode): point RAGFlow to a Docling Serve endpoint.
To enable remote mode, set:
DOCLING_SERVER_URL=http://your-docling-serve-host:5001
Behavior:
- When
DOCLING_SERVER_URLis set, RAGFlow sends PDFs to Docling Serve using/v1/convert/source(and falls back to/v1alpha/convert/sourcefor older servers). - When
DOCLING_SERVER_URLis not set, RAGFlow uses local in-process Docling.
How to use PaddleOCR for document parsing?
From v0.24.0 onwards, RAGFlow includes PaddleOCR as an optional PDF parser. Please note that RAGFlow acts only as a remote client for PaddleOCR, calling the PaddleOCR API to parse PDFs and reading the returned files.
There are two main ways to configure and use PaddleOCR in RAGFlow:
1. Using PaddleOCR Official API
This method uses PaddleOCR's official API service with an access token.
Step 1: Configure RAGFlow
-
Via Environment Variables:
# In your docker/.env file:
PADDLEOCR_API_URL=https://your-paddleocr-api-endpoint
PADDLEOCR_ALGORITHM=PaddleOCR-VL
PADDLEOCR_ACCESS_TOKEN=your-access-token-here -
Via UI:
- Navigate to Model providers page
- Add a new OCR model with factory type "PaddleOCR"
- Configure the following fields:
- PaddleOCR API URL: Your PaddleOCR API endpoint
- PaddleOCR Algorithm: Select the algorithm corresponding to the API endpoint
- AI Studio Access Token: Your access token for the PaddleOCR API
Step 2: Usage in Dataset Configuration
- In your dataset's Configuration page, find the Ingestion pipeline section
- If using built-in chunking methods that support PDF parsing, select PaddleOCR from the PDF parser dropdown
- If using custom ingestion pipeline, select PaddleOCR in the Parser component
Notes:
- To obtain the API URL, visit the PaddleOCR official website, click the API button, choose the example code for the specific algorithm you want to use (e.g., PaddleOCR-VL), and copy the
API_URL. - Access tokens can be obtained from the AI Studio platform.
- This method requires internet connectivity to reach the official PaddleOCR API.
2. Using Self-Hosted PaddleOCR Service
This method allows you to deploy your own PaddleOCR service and use it without an access token.
Step 1: Deploy PaddleOCR Service Follow the PaddleOCR serving documentation to deploy your own service. For layout parsing, you can use an endpoint like:
http://localhost:8080/layout-parsing
Step 2: Configure RAGFlow
-
Via Environment Variables:
PADDLEOCR_API_URL=http://localhost:8080/layout-parsing
PADDLEOCR_ALGORITHM=PaddleOCR-VL
# No access token required for self-hosted service -
Via UI:
- Navigate to Model providers page
- Add a new OCR model with factory type "PaddleOCR"
- Configure the following fields:
- PaddleOCR API URL: The endpoint of your deployed service
- PaddleOCR Algorithm: Select the algorithm corresponding to the deployed service
- AI Studio Access Token: Leave empty
Step 3: Usage in Dataset Configuration
- In your dataset's Configuration page, find the Ingestion pipeline section
- If using built-in chunking methods that support PDF parsing, select PaddleOCR from the PDF parser dropdown
- If using custom ingestion pipeline, select PaddleOCR in the Parser component
Environment Variables Summary
| Environment Variable | Description | Default | Required |
|---|---|---|---|
PADDLEOCR_API_URL | PaddleOCR API endpoint URL | "" | Yes, when using environment variables |
PADDLEOCR_ALGORITHM | Algorithm to use for parsing | "PaddleOCR-VL" | No |
PADDLEOCR_ACCESS_TOKEN | Access token for official API | None | Only when using official API |
Environment variables can be used for auto-provisioning, but are not required if configuring via UI. When environment variables are set, these values are used to auto-provision a PaddleOCR model for the tenant on first use.
How do I use Ollama with RAGFlow for local LLM inference?
RAGFlow supports Ollama as a local model provider for private, offline inference.
Step 1: Start Ollama and pull a model
export OLLAMA_HOST=0.0.0.0
ollama serve
ollama pull llama3
Step 2: Add Ollama in RAGFlow
- Go to Settings > Model providers > Ollama.
- Set the Base URL to
http://host.docker.internal:11434(Docker) orhttp://localhost:11434(bare-metal). - Enter the model name (e.g.,
llama3) and click Save.
Step 3: Use Ollama in your assistant
- Open an assistant's Configuration page and select the Ollama model under Chat model.