9 min read
RAGFlow 0.26 — API & Model Provider Refactoring, Incremental Data Sources
5 min read
RAGFlow 0.25 — Ingestion pipeline, agent sandbox, and user-level memory
9 min read
Data foundation in the era of agent harness - why RAGFlow is changing
4 min read
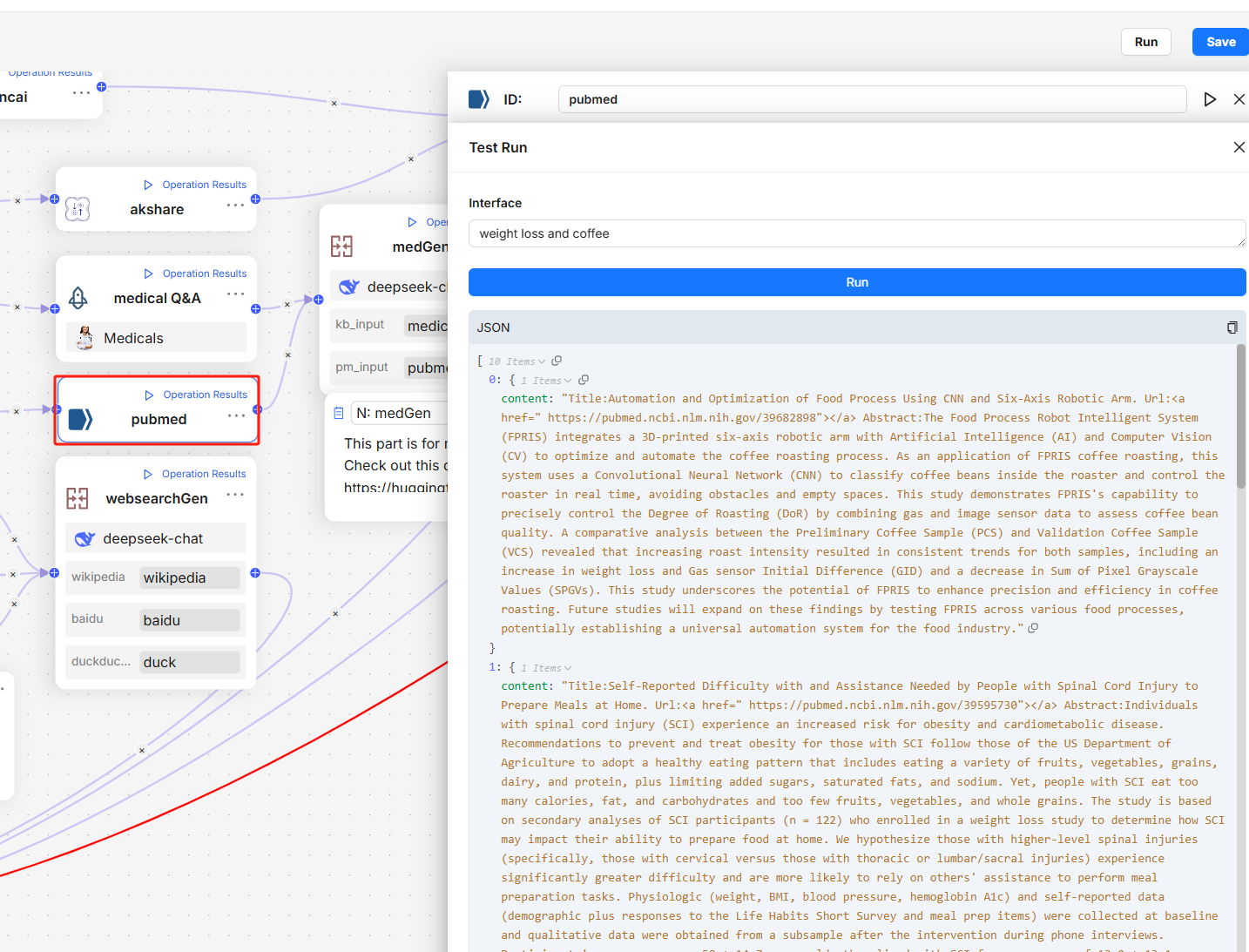
RAGFlow x OpenClaw - The Enterprise-aware Claw
2 min read
RAGFlow online service domain switch
4 min read
RAGFlow 0.24.0 — Memory API, knowledge base governance and Agent chat history
18 min read
RAGFlow 0.23.0 — Advancing Memory, RAG, and Agent Performance
37 min read
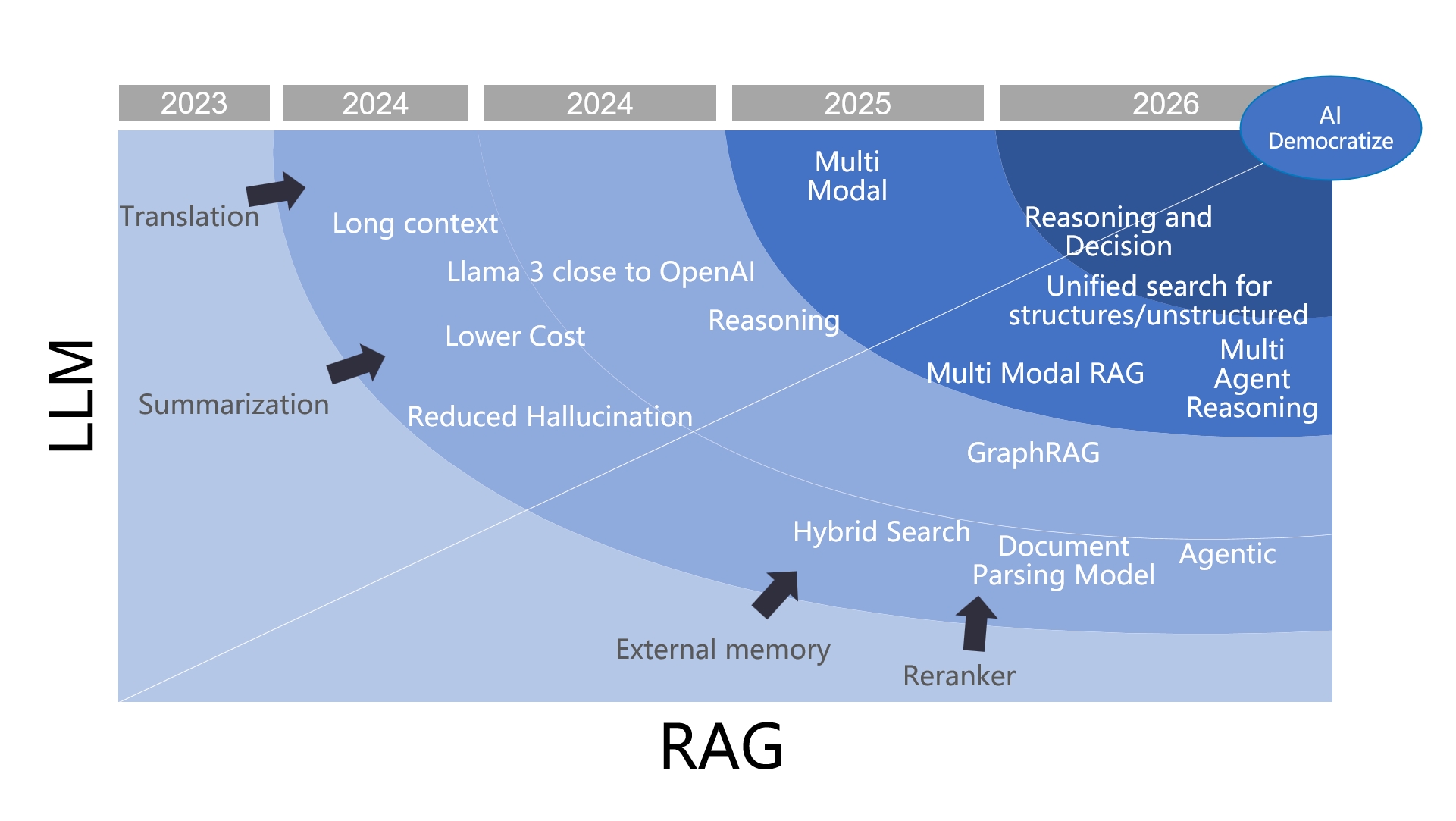
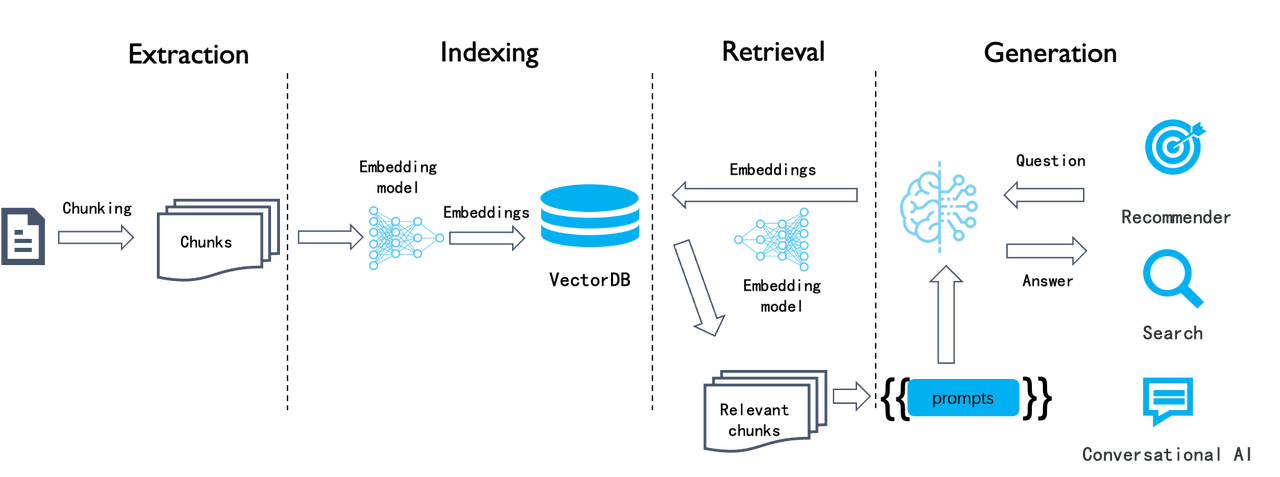
From RAG to Context - A 2025 year-end review of RAG
3 min read
RAGFlow’s Seamless Upgrade - from 0.21 to 0.22 and Beyond
6 min read
RAGFlow 0.22.0 Overview — Supported Data Sources, Enhanced Parser, Agent Optimizations, and Admin UI
16 min read
RAGFlow in Practice - Building an Agent for Deep-Dive Analysis of Company Research Reports
3 min read
RAGFlow Named Among GitHub’s Fastest-Growing Open Source Projects, Reflecting Surging Demand for Production-Ready AI
18 min read
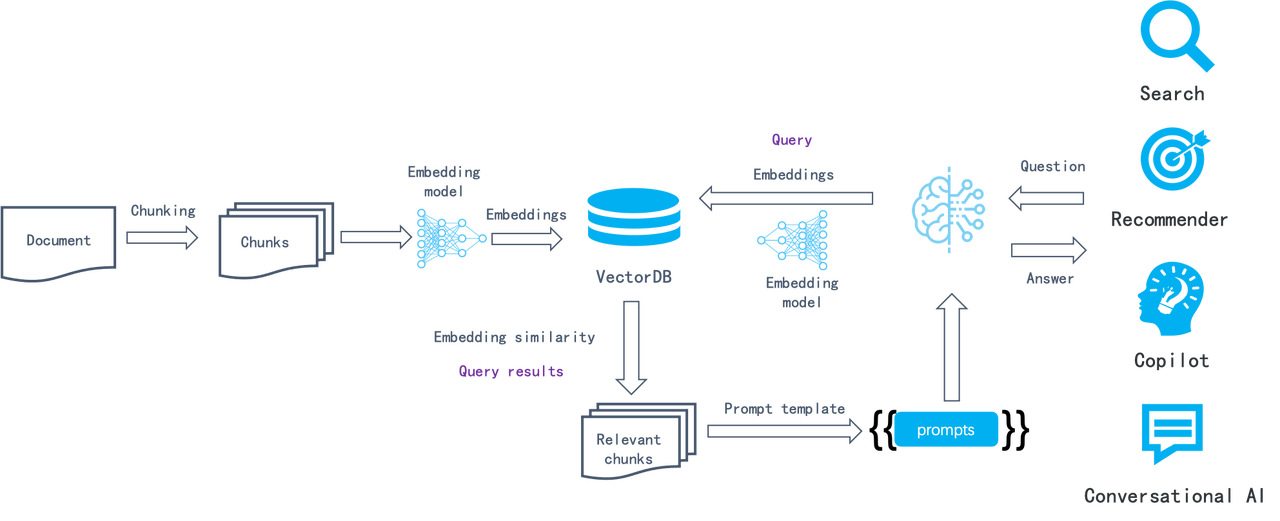
Is data processing like building with lego? Here is a detailed explanation of the ingestion pipeline.
11 min read
Bid Farewell to Complexity — RAGFlow CLI Makes Back-end Management a Breeze
10 min read
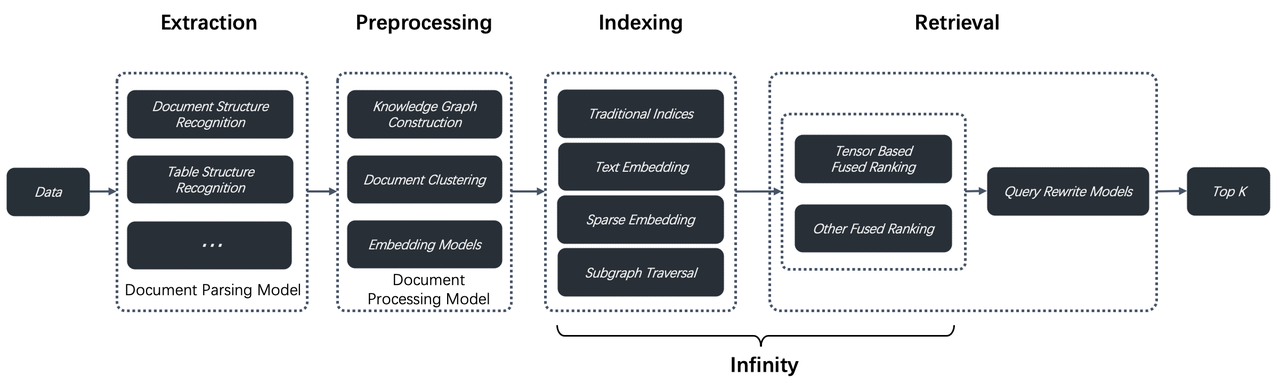
500 Percent Faster Vector Retrieval! 90 Percent Memory Savings! Three Groundbreaking Technologies in Infinity v0.6.0 That Revolutionize HNSW
10 min read
RAGFlow 0.21.0 - Ingestion Pipeline, Long-Context RAG, and Admin CLI
7 min read
Tutorial - Build an E-Commerce Customer Support Agent Using RAGFlow
7 min read
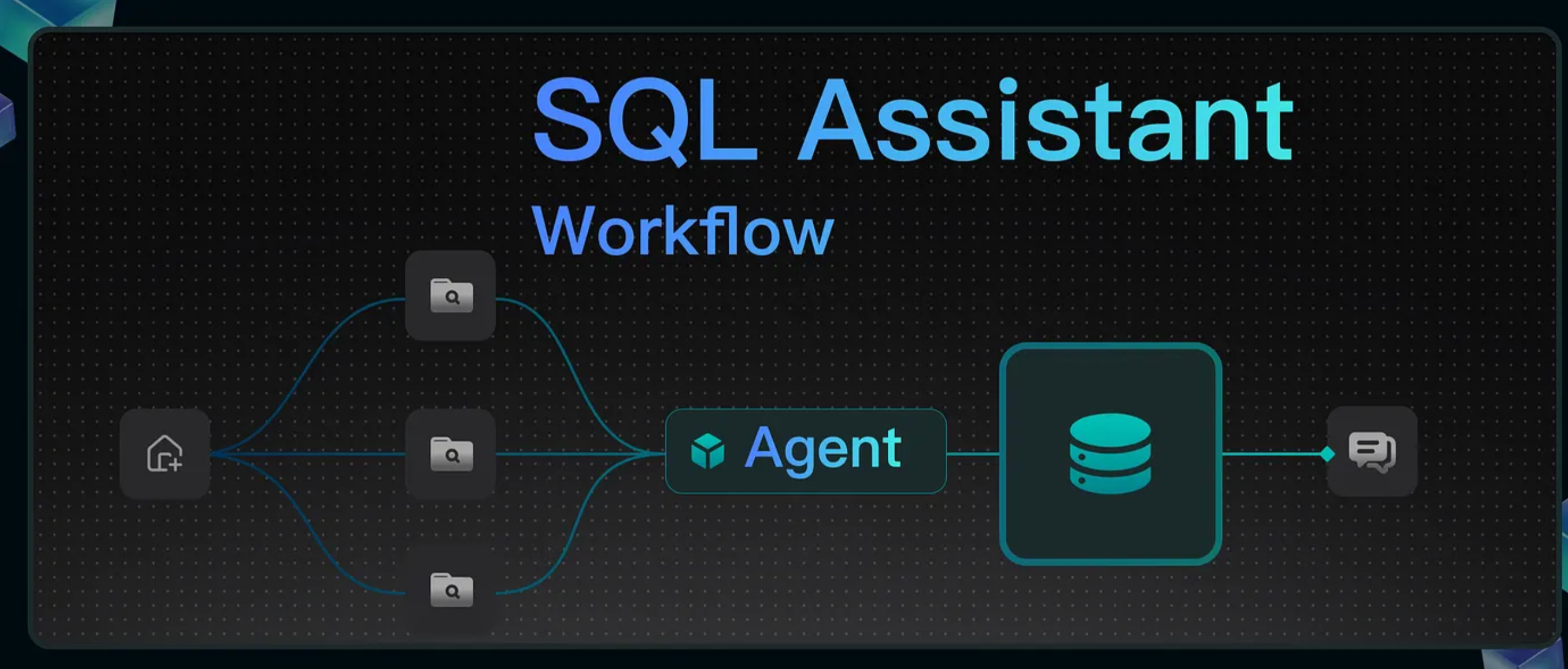
Tutorial - Building a SQL Assistant Workflow
13 min read
RAGFlow 0.20.0 - Multi-Agent Deep Research
8 min read
Agentic Workflow - What's inside RAGFlow 0.20.0
14 min read
RAG at the Crossroads - Mid-2025 Reflections on AI’s Incremental Evolution
37 min read
The Rise and Evolution of RAG in 2024 A Year in Review
6 min read
A deep dive into RAGFlow v0.15.0
9 min read
What Infrastructure Capabilities does RAG Need beyond Hybrid Search
5 min read
Implementing Text2SQL with RAGFlow
6 min read
How Our GraphRAG Reveals the Hidden Relationships of Jon Snow and the Mother of Dragons
8 min read
From RAG 1.0 to RAG 2.0, What Goes Around Comes Around
8 min read
RAGFlow Enters Agentic Era
6 min read
Agentic RAG - Definition and Low-code Implementation
4 min read
Implementing a long-context RAG based on RAPTOR