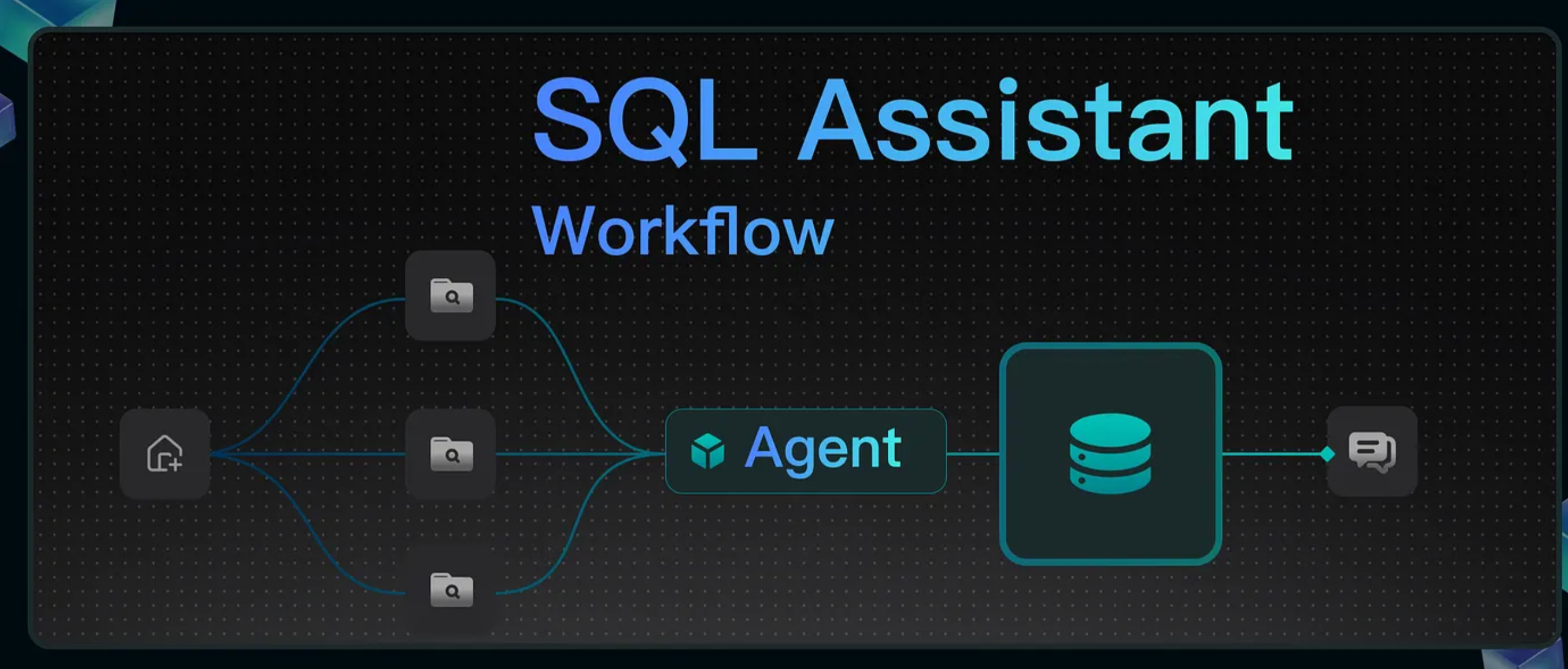
Oct 30, 202516 min readRAGFlow in Practice - Building an Agent for Deep-Dive Analysis of Company Research Reports