Bid Farewell to Complexity — RAGFlow CLI Makes Back-end Management a Breeze

To meet the refined requirements for system operation and maintenance monitoring as well as user account management, especially addressing practical issues currently faced by RAGFlow users, such as "the inability of users to recover lost passwords on their own" and "difficulty in effectively controlling account statuses," RAGFlow has officially launched a professional back-end management command-line tool.
This tool is based on a clear client-server architecture. By adopting the design philosophy of functional separation, it constructs an efficient and reliable system management channel, enabling administrators to achieve system recovery and permission control at the fundamental level.
The specific architectural design is illustrated in the following diagram:
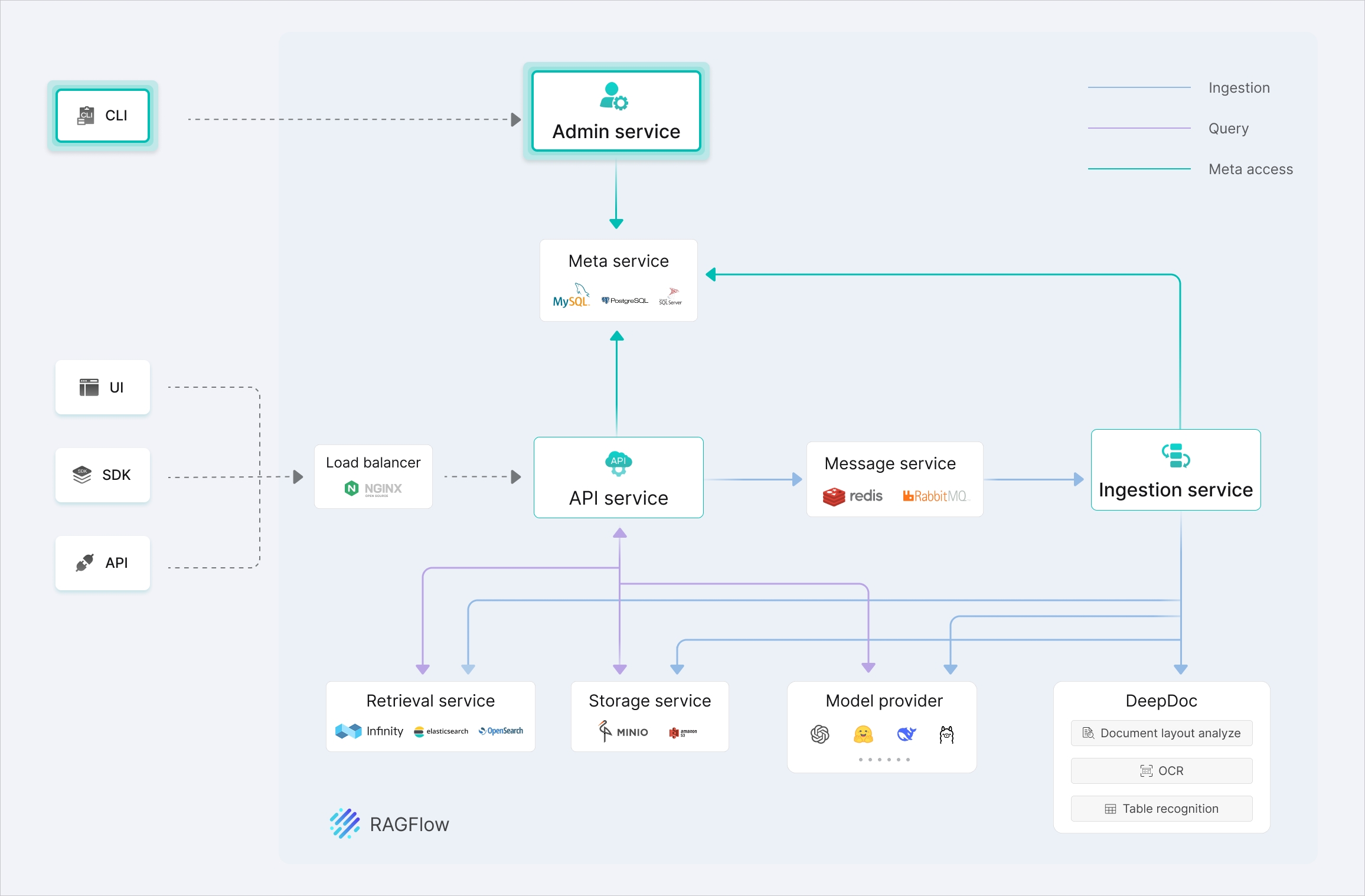
Through this tool, RAGFlow users can gain a one-stop overview of the operational status of the RAGFlow Server as well as components such as MySQL, Elasticsearch, Redis, MinIO, and Infinity. It also supports comprehensive user lifecycle management, including account creation, status control, password reset, and data cleanup.
Start the service
If you deploy RAGFlow via Docker, please modify the docker/docker_compose.yml file and add parameters to the service startup command.
command:
- --enable-adminserver
If you are deploying RAGFlow from the source code, you can directly execute the following command to start the management server:
python3 admin/server/admin_server.py
After the server starts, it listens on port 9381 by default, waiting for client connections. If you need to use a different port, please modify the ADMIN_SVR_HTTP_PORT configuration item in the docker/.env file.
Install the client and connect to the management service
It is recommended to use pip to install the specified version of the client:
pip install ragflow-cli==0.21.0
Version 0.21.0 is the current latest version. Please ensure that the version of ragflow-cli matches the version of the RAGFlow server to avoid compatibility issues:
ragflow-cli -h 127.0.0.1 -p 9381
Here, -h specifies the server IP, and -p specifies the server port. If the server is deployed at a different address or port, please adjust the parameters accordingly.
For the first login, enter the default administrator password admin. After successfully logging in, it is recommended to promptly change the default password in the command-line tool to enhance security.
Command Usage Guide
By entering the following commands through the client, you can conveniently manage users and monitor the operational status of the service.
Interactive Feature Description
- Supports using arrow keys to move the cursor and review historical commands.
- Pressing
Ctrl+Callows you to terminate the current interaction at any time. - If you need to copy content, please avoid using
Ctrl+Cto prevent accidentally interrupting the process.
Command Format Specifications
- All commands are case-insensitive and must end with a semicolon
;. - Text parameters such as usernames and passwords need to be enclosed in single quotes
'or double quotes". - Special characters like
\,', and"are prohibited in passwords.
Service Management Commands
LIST SERVICES;
- List the operational status of RAGFlow backend services and all associated middleware.
Usage Example
admin> list services;
Listing all services
+-------------------------------------------------------------------------------------------+-----------+----+---------------+-------+----------------+---------+
| extra | host | id | name | port | service_type | status |
+-------------------------------------------------------------------------------------------+-----------+----+---------------+-------+----------------+---------+
| {} | 0.0.0.0 | 0 | ragflow_0 | 9380 | ragflow_server | Timeout |
| {'meta_type': 'mysql', 'password': 'infini_rag_flow', 'username': 'root'} | localhost | 1 | mysql | 5455 | meta_data | Alive |
| {'password': 'infini_rag_flow', 'store_type': 'minio', 'user': 'rag_flow'} | localhost | 2 | minio | 9000 | file_store | Alive |
| {'password': 'infini_rag_flow', 'retrieval_type': 'elasticsearch', 'username': 'elastic'} | localhost | 3 | elasticsearch | 1200 | retrieval | Alive |
| {'db_name': 'default_db', 'retrieval_type': 'infinity'} | localhost | 4 | infinity | 23817 | retrieval | Timeout |
| {'database': 1, 'mq_type': 'redis', 'password': 'infini_rag_flow'} | localhost | 5 | redis | 6379 | message_queue | Alive |
+-------------------------------------------------------------------------------------------+-----------+----+---------------+-------+----------------+---------+
List the operational status of RAGFlow backend services and all associated middleware.
SHOW SERVICE <id>;
- Query the detailed operational status of the specified service.
<id>: Command:LIST SERVICES;The service identifier ID in the displayed results.
Usage Example:
- Query the RAGFlow backend service:
admin> show service 0;
Showing service: 0
Service ragflow_0 is alive. Detail:
Confirm elapsed: 4.1 ms.
The response indicates that the RAGFlow backend service is online, with a response time of 4.1 milliseconds.
- Query the MySQL service:
admin> show service 1;
Showing service: 1
Service mysql is alive. Detail:
+---------+----------+------------------+------+------------------+------------------------+-------+-----------------+
| command | db | host | id | info | state | time | user |
+---------+----------+------------------+------+------------------+------------------------+-------+-----------------+
| Daemon | None | localhost | 5 | None | Waiting on empty queue | 86356 | event_scheduler |
| Sleep | rag_flow | 172.18.0.6:56788 | 8790 | None | | 2 | root |
| Sleep | rag_flow | 172.18.0.6:53482 | 8791 | None | | 73 | root |
| Query | rag_flow | 172.18.0.6:56794 | 8795 | SHOW PROCESSLIST | init | 0 | root |
+---------+----------+------------------+------+------------------+------------------------+-------+-----------------+
The response indicates that the MySQL service is online, with the current connection and execution status shown in the table above.
- Query the MinIO service:
admin> show service 2;
Showing service: 2
Service minio is alive. Detail:
Confirm elapsed: 2.3 ms.
The response indicates that the MinIO service is online, with a response time of 2.3 milliseconds.
- Query the Elasticsearch service:
admin> show service 3;
Showing service: 3
Service elasticsearch is alive. Detail:
+----------------+------+--------------+---------+----------------+--------------+---------------+--------------+------------------------------+----------------------------+-----------------+-------+---------------+---------+-------------+---------------------+--------+------------+--------------------+
| cluster_name | docs | docs_deleted | indices | indices_shards | jvm_heap_max | jvm_heap_used | jvm_versions | mappings_deduplicated_fields | mappings_deduplicated_size | mappings_fields | nodes | nodes_version | os_mem | os_mem_used | os_mem_used_percent | status | store_size | total_dataset_size |
+----------------+------+--------------+---------+----------------+--------------+---------------+--------------+------------------------------+----------------------------+-----------------+-------+---------------+---------+-------------+---------------------+--------+------------+--------------------+
| docker-cluster | 8 | 0 | 1 | 2 | 3.76 GB | 2.15 GB | 21.0.1+12-29 | 17 | 757 B | 17 | 1 | ['8.11.3'] | 7.52 GB | 2.30 GB | 31 | green | 226 KB | 226 KB |
+----------------+------+--------------+---------+----------------+--------------+---------------+--------------+------------------------------+----------------------------+-----------------+-------+---------------+---------+-------------+---------------------+--------+------------+--------------------+
The response indicates that the Elasticsearch cluster is operating normally, with specific metrics including document count, index status, memory usage, etc.
- Query the Infinity service:
admin> show service 4;
Showing service: 4
Fail to show service, code: 500, message: Infinity is not in use.
The response indicates that Infinity is not currently in use by the RAGFlow system.
admin> show service 4;
Showing service: 4
Service infinity is alive. Detail:
+-------+--------+----------+
| error | status | type |
+-------+--------+----------+
| | green | infinity |
+-------+--------+----------+
After enabling Infinity and querying again, the response indicates that the Infinity service is online and in good condition.
- Query the Redis service:
admin> show service 5;
Showing service: 5
Service redis is alive. Detail:
+-----------------+-------------------+---------------------------+-------------------------+---------------+-------------+--------------------------+---------------------+-------------+
| blocked_clients | connected_clients | instantaneous_ops_per_sec | mem_fragmentation_ratio | redis_version | server_mode | total_commands_processed | total_system_memory | used_memory |
+-----------------+-------------------+---------------------------+-------------------------+---------------+-------------+--------------------------+---------------------+-------------+
| 0 | 3 | 10 | 3.03 | 7.2.4 | standalone | 404098 | 30.84G | 1.29M |
+-----------------+-------------------+---------------------------+-------------------------+---------------+-------------+--------------------------+---------------------+-------------+
The response indicates that the Redis service is online, with the version number, deployment mode, and resource usage shown in the table above.
User Management Commands
LIST USERS;
- List all users in the RAGFlow system.
Usage Example:
admin> list users;
Listing all users
+-------------------------------+----------------------+-----------+----------+
| create_date | email | is_active | nickname |
+-------------------------------+----------------------+-----------+----------+
| Mon, 13 Oct 2025 15:58:42 GMT | admin@ragflow.io | 1 | admin |
| Mon, 13 Oct 2025 15:54:34 GMT | lynn_inf@hotmail.com | 1 | Lynn |
+-------------------------------+----------------------+-----------+----------+
The response indicates that there are currently two users in the system, both of whom are enabled.
Among them, admin@ragflow.io is the administrator account, which is automatically created during the initial system startup.
SHOW USER <username>;
- Query detailed user information by email.
<username>: The user's email address, which must be enclosed in single quotes'or double quotes".
Usage Example:
- Query the administrator user
admin> show user "admin@ragflow.io";
Showing user: admin@ragflow.io
+-------------------------------+------------------+-----------+--------------+------------------+--------------+----------+-----------------+---------------+--------+-------------------------------+
| create_date | email | is_active | is_anonymous | is_authenticated | is_superuser | language | last_login_time | login_channel | status | update_date |
+-------------------------------+------------------+-----------+--------------+------------------+--------------+----------+-----------------+---------------+--------+-------------------------------+
| Mon, 13 Oct 2025 15:58:42 GMT | admin@ragflow.io | 1 | 0 | 1 | True | English | None | None | 1 | Mon, 13 Oct 2025 15:58:42 GMT |
+-------------------------------+------------------+-----------+--------------+------------------+--------------+----------+-----------------+---------------+--------+-------------------------------+
The response indicates that admin@ragflow.io is a super administrator and is currently enabled.
- Query a regular user
admin> show user "lynn_inf@hotmail.com";
Showing user: lynn_inf@hotmail.com
+-------------------------------+----------------------+-----------+--------------+------------------+--------------+----------+-------------------------------+---------------+--------+-------------------------------+
| create_date | email | is_active | is_anonymous | is_authenticated | is_superuser | language | last_login_time | login_channel | status | update_date |
+-------------------------------+----------------------+-----------+--------------+------------------+--------------+----------+-------------------------------+---------------+--------+-------------------------------+
| Mon, 13 Oct 2025 15:54:34 GMT | lynn_inf@hotmail.com | 1 | 0 | 1 | False | English | Mon, 13 Oct 2025 15:54:33 GMT | password | 1 | Mon, 13 Oct 2025 17:24:09 GMT |
+-------------------------------+----------------------+-----------+--------------+------------------+--------------+----------+-------------------------------+---------------+--------+-------------------------------+
The response indicates that lynn_inf@hotmail.com is a regular user who logs in via password, with the last login time shown as the provided timestamp.
CREATE USER <username> <password>;
- Create a new user.
<username>: The user's email address must comply with standard email format specifications.<password>: The user's password must not contain special characters such as\,', or".
Usage Example:
admin> create user "example@ragflow.io" "psw";
Create user: example@ragflow.io, password: psw, role: user
+----------------------------------+--------------------+----------------------------------+--------------+---------------+----------+
| access_token | email | id | is_superuser | login_channel | nickname |
+----------------------------------+--------------------+----------------------------------+--------------+---------------+----------+
| be74d786a9b911f0a726d68c95a0776b | example@ragflow.io | be74d6b4a9b911f0a726d68c95a0776b | False | password | |
+----------------------------------+--------------------+----------------------------------+--------------+---------------+----------+
A regular user has been successfully created. Personal information such as nickname and avatar can be set by the user themselves after logging in and accessing the profile page.
ALTER USER PASSWORD <username> <new_password>;
- Change the user's password.
<username>: User email address<password>: New password (must not be the same as the old password and must not contain special characters)
Usage Example:
admin> alter user password "example@ragflow.io" "psw";
Alter user: example@ragflow.io, password: psw
Same password, no need to update!
When the new password is the same as the old password, the system prompts that no change is needed.
admin> alter user password "example@ragflow.io" "new psw";
Alter user: example@ragflow.io, password: new psw
Password updated successfully!
The password has been updated successfully. The user can log in with the new password thereafter.
ALTER USER ACTIVE <username> <on/off>;
- Enable or disable a user.
<username>: User email address<on/off>: Enabled or disabled status
Usage Example:
admin> alter user active "example@ragflow.io" off;
Alter user example@ragflow.io activate status, turn off.
Turn off user activate status successfully!
The user has been successfully disabled. Only users in a disabled state can be deleted.
DROP USER <username>;
- Delete the user and all their associated data
<username>: User email address
Important Notes:
- Only disabled users can be deleted.
- Before proceeding, ensure that all necessary data such as knowledge bases and files that need to be retained have been transferred to other users.
- This operation will permanently delete the following user data:
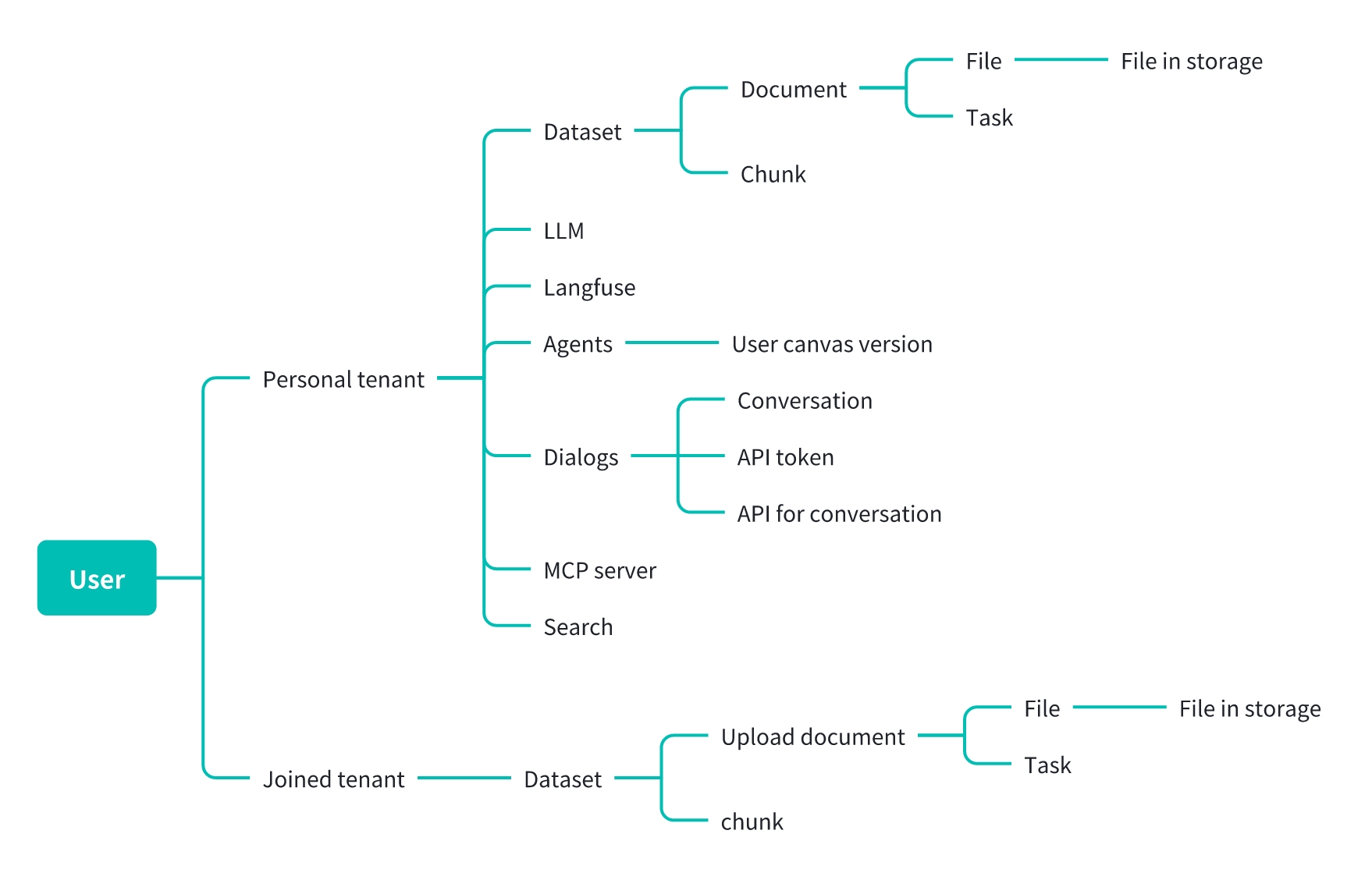
All knowledge bases created by the user, uploaded files, and configured agents, as well as files uploaded by the user in others' knowledge bases, will be permanently deleted. This operation is irreversible, so please proceed with extreme caution.
- The deletion command is idempotent. If the system fails or the operation is interrupted during the deletion process, the command can be re-executed after troubleshooting to continue deleting the remaining data.
Usage Example:
- User Successfully Deleted
admin> drop user "example@ragflow.io";
Drop user: example@ragflow.io
Successfully deleted user. Details:
Start to delete owned tenant.
- Deleted 2 tenant-LLM records.
- Deleted 0 langfuse records.
- Deleted 1 tenant.
- Deleted 1 user-tenant records.
- Deleted 1 user.
Delete done!
The response indicates that the user has been successfully deleted, and it lists detailed steps for data cleanup.
- Deleting Super Administrator (Prohibited Operation)
admin> drop user "admin@ragflow.io";
Drop user: admin@ragflow.io
Fail to drop user, code: -1, message: Can't delete the super user.
The response indicates that the deletion failed. The super administrator account is protected and cannot be deleted, even if it is in a disabled state.
Data and Agent Management Commands
LIST DATASETS OF <username>;
- List all knowledge bases of the specified user
<username>: User email address
Usage Example:
admin> list datasets of "lynn_inf@hotmail.com";
Listing all datasets of user: lynn_inf@hotmail.com
+-----------+-------------------------------+---------+----------+-----------------+------------+--------+-----------+-------------------------------+
| chunk_num | create_date | doc_num | language | name | permission | status | token_num | update_date |
+-----------+-------------------------------+---------+----------+-----------------+------------+--------+-----------+-------------------------------+
| 8 | Mon, 13 Oct 2025 15:56:43 GMT | 1 | English | primary_dataset | me | 1 | 3296 | Mon, 13 Oct 2025 15:57:54 GMT |
+-----------+-------------------------------+---------+----------+-----------------+------------+--------+-----------+-------------------------------+
The response shows that the user has one private knowledge base, with detailed information such as the number of documents and segments displayed in the table above.
LIST AGENTS OF <username>;
- List all Agents of the specified user
<username>: User email address
Usage Example:
admin> list agents of "lynn_inf@hotmail.com";
Listing all agents of user: lynn_inf@hotmail.com
+-----------------+-------------+------------+----------------+
| canvas_category | canvas_type | permission | title |
+-----------------+-------------+------------+----------------+
| agent_canvas | None | me | finance_helper |
+-----------------+-------------+------------+----------------+
The response indicates that the user has one private Agent, with detailed information shown in the table above.
Other commands
- ? or \help
Display help information.
- \q or \quit
Follow-up plan
We are always committed to enhancing the system management experience and overall security. Building on its existing robust features, the RAGFlow back-end management tool will continue to evolve. In addition to the current efficient and flexible command-line interface, we are soon launching a professional system management UI, enabling administrators to perform all operational and maintenance tasks in a more secure and intuitive graphical environment.
To strengthen permission control, the system status information currently visible in the ordinary user interface will be revoked. After the future launch of the professional management UI, access to the core operational status of the system will be restricted to administrators only. This will effectively address the current issue of excessive permission exposure and further reinforce the system's security boundaries.
In addition, we will also roll out more fine-grained management features sequentially, including:
- Fine-grained control over Datasets and Agents
- User Team collaboration management mechanisms
- Enhanced system monitoring and auditing capabilities
These improvements will establish a more comprehensive enterprise-level management ecosystem, providing administrators with a more all-encompassing and convenient system control experience.